Pag-encode ng data
Panimula at notasyon
Para magamit ang isang quantum algorithm, kailangang mailagay ang klasikal na data sa isang quantum circuit. Karaniwang tinatawag itong encoding ng data, pero tinatawag din itong loading ng data. Alalahanin mula sa mga nakaraang aralin ang konsepto ng feature mapping — isang pagmamapa ng mga feature ng data mula sa isang espasyo patungo sa isa pa. Ang simpleng paglipat ng klasikal na data sa isang quantum computer ay isang uri ng pagmamapa, at maaaring tawagin na feature mapping. Sa praktika, ang mga built-in na feature mapping sa Qiskit (tulad ng z_feature_map at zz_feature_map) ay karaniwang may kasamang mga rotation layer at entangling layer na nagpapalawak ng estado sa maraming dimensyon sa Hilbert space. Ang proseso ng encoding na ito ay isang kritikal na bahagi ng mga quantum machine learning algorithm at direktang nakakaapekto sa kanilang kakayahang pangkomputa.
Ang ilang mga teknik ng encoding na nakalista sa ibaba ay maaaring mahusay na gayahin nang klasikal; partikular na malinaw ito sa mga paraan ng encoding na nagbibigay ng mga product state (ibig sabihin, hindi nila inaasosya ang mga qubit). At tandaan na ang quantum utility ay pinaka-malamang na matatagpuan kung saan ang quantum-like na kumplikado ng dataset ay naaayon sa paraan ng encoding. Kaya't malamang na magsusulat ka ng sariling mga encoding circuit. Dito, nagpapakita tayo ng malawak na hanay ng mga posibleng estratehiya ng encoding para makapaghambing at makapagkumpara ng iba't ibang pamamaraan, at para makita kung ano ang posible. May ilang napaka-pangkalahatang pahayag na maaaring gawin tungkol sa pagiging kapaki-pakinabang ng mga teknik sa encoding. Halimbawa, ang efficient_su2 (tingnan sa ibaba) na may kumpletong entangling scheme ay mas malamang na makakuha ng mga quantum feature ng data kaysa sa mga pamamaraang nagbibigay ng product state (tulad ng z_feature_map). Ngunit hindi ito nangangahulugang sapat ang efficient_su2, o sapat na akma sa iyong dataset, para magbunga ng quantum speed-up. Nangangailangan iyon ng maingat na pagsasaalang-alang sa istruktura ng data na kino-modelo o ikinlasipika. May balancing act din pagdating sa lalim ng circuit, dahil maraming feature map na ganap na nag-iimplicate ng mga qubit sa isang circuit ay nagbubunga ng napakalalim na mga circuit — masyadong malalim para makakuha ng magagamit na resulta sa mga kasalukuyang quantum computer.
Notasyon
Ang isang dataset ay isang set ng na mga data vector: , kung saan ang bawat vector ay may na dimensyon, iyon ay, . Maaari itong palawigin para sa mga kumplikadong feature ng data. Sa araling ito, paminsan-minsan ay gagamitin natin ang mga notasyong ito para sa buong set at ang mga partikular na elemento nito tulad ng . Ngunit kadalasan ay mag-iisip tayo tungkol sa pag-load ng isang vector mula sa ating dataset sa isang pagkakataon, at madalas na simpleng tatawagin ang isang vector ng na feature bilang .
Bukod dito, karaniwang ginagamit ang simbolo para tumukoy sa feature mapping ng data vector . Sa quantum computing lalo na, karaniwang ginagamit ang para tumukoy sa mga pagmamapa — isang notasyon na nagpapalakas ng unitary na katangian ng mga operasyong ito. Maaaring tamang gamitin ang parehong simbolo para sa pareho; parehong feature mapping ang dalawa. Sa buong kursong ito, ginagamit natin:
- kapag tinatalakay ang mga feature mapping sa machine learning sa pangkalahatan, at
- kapag tinatalakay ang mga circuit implementation ng feature mapping.
Normalization at pagkawala ng impormasyon
Sa klasikal na machine learning, ang mga feature ng training data ay madalas na "nino-normalize" o binabago ang sukat, na kadalasang nagpapabuti ng pagganap ng modelo. Isang karaniwang paraan nito ay ang paggamit ng min-max normalization o standardization. Sa min-max normalization, ang mga feature column ng data matrix (sabihin, feature ) ay nino-normalize:
kung saan ang min at max ay tumutukoy sa pinakamaliit at pinakamalaking halaga ng feature sa na data vector sa dataset . Lahat ng halaga ng feature ay napapaloob sa unit interval: para sa lahat ng , .
Ang normalization ay isang pangunahing konsepto rin sa quantum mechanics at quantum computing, ngunit bahagyang naiiba ito sa min-max normalization. Ang normalization sa quantum mechanics ay nangangailangan na ang haba (sa konteksto ng quantum computing, ang 2-norm) ng isang state vector ay katumbas ng isa: , na tinitiyak na ang mga probability ng pagsukat ay nagkakabuong 1. Nino-normalize ang estado sa pamamagitan ng paghahati sa 2-norm; iyon ay, sa pamamagitan ng pag-rescale ng
Sa quantum computing at quantum mechanics, hindi ito isang normalization na ipinapataw ng mga tao sa data, kundi isang pangunahing katangian ng mga quantum state. Depende sa iyong encoding scheme, maaaring makaapekto ang limitasyong ito sa kung paano nire-rescale ang iyong data. Halimbawa, sa amplitude encoding (tingnan sa ibaba), nino-normalize ang data vector ayon sa kinakailangan ng quantum mechanics, at ito ay nakakaapekto sa sukat ng data na ine-encode. Sa phase encoding, inirerekomenda na i-rescale ang mga halaga ng feature bilang para walang pagkawala ng impormasyon dahil sa modulo- na epekto ng pag-encode sa isang qubit phase angle[1,2].
Mga paraan ng encoding
Sa susunod na ilang seksyon, magsasanggunian tayo sa isang maliit na halimbawang klasikal na dataset na binubuo ng na data vector, bawat isa ay may na feature:
Sa notasyong inilarawan sa itaas, maaari nating sabihin na ang na feature ng na data vector sa ating set ay halimbawa.
Basis encoding
Ang basis encoding ay nagko-encode ng klasikal na -bit na string sa isang computational basis state ng isang -qubit na sistema. Halimbawa, Maaari itong irepresenta bilang isang -bit na string bilang , at ng isang -qubit na sistema bilang quantum state na . Sa pangkalahatan, para sa isang -bit na string: , ang katumbas na -qubit na estado ay na may para sa . Tandaan na para lamang ito sa isang feature.
Ang basis encoding sa quantum computing ay kumakatawan sa bawat klasikal na bit bilang isang hiwalay na qubit, na direktang nagmamapa ng binary na representasyon ng data sa mga quantum state sa computational basis. Kapag kailangan ng encoding ng maraming feature, bawat feature ay unang kino-convert sa binary form nito at pagkatapos ay itinalaga sa isang natatanging grupo ng mga qubit — isang grupo bawat feature — kung saan ang bawat qubit ay sumasalamin sa isang bit sa binary na representasyon ng feature na iyon.
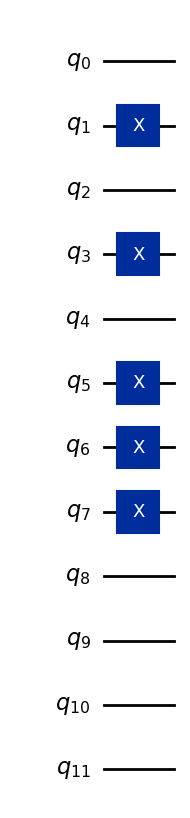
Bilang halimbawa, i-encode natin ang vector (5, 7, 0).
Ipagpalagay na lahat ng feature ay naka-imbak sa apat na bit (higit pa sa kailangan natin, ngunit sapat para kumatawan sa anumang integer na isang digit sa base 10):
5 → binary 0101
7 → binary 0111
0 → binary 0000
Ang mga bit string na ito ay itinalaga sa tatlong set ng apat na qubit, kaya ang kabuuang 12-qubit basis state ay:
Dito, ang unang apat na qubit ay kumakatawan sa unang feature, ang susunod na apat na qubit ay sa ikalawang feature, at ang huling apat na qubit ay sa ikatlong feature. Ang code sa ibaba ay nagco-convert ng data vector (5,7,0) sa isang quantum state, at ginawang pangkalahatan para magawa rin ito para sa iba pang single-digit na feature.
# Added by doQumentation — required packages for this notebook
!pip install -q matplotlib numpy qiskit
from qiskit import QuantumCircuit
# Data point to encode
x = 5 # binary: 0101
y = 7 # binary: 0111
z = 0 # binary: 0000
# Convert each to 4-bit binary list
x_bits = [int(b) for b in format(x, "04b")] # [0,1,0,1]
y_bits = [int(b) for b in format(y, "04b")] # [0,1,1,1]
z_bits = [int(b) for b in format(z, "04b")] # [0,0,0,0]
# Combine all bits
all_bits = x_bits + y_bits + z_bits # [0,1,0,1,0,1,1,1,0,0,0,0]
# Initialize a 12-qubit quantum circuit
qc = QuantumCircuit(12)
# Apply x-gates where the bit is 1
for idx, bit in enumerate(all_bits):
if bit == 1:
qc.x(idx)
qc.draw("mpl")
Suriin ang iyong pag-unawa
Basahin ang tanong sa ibaba, isipin ang iyong sagot, pagkatapos ay i-click ang tatsulok para makita ang solusyon.
Sumulat ng code para i-encode ang unang vector sa ating halimbawang dataset :
gamit ang basis encoding.
Sagot:
import math
from qiskit import QuantumCircuit
# Data point to encode
x = 4 # binary: 0100
y = 8 # binary: 1000
z = 5 # binary: 0101
# Convert each to 4-bit binary list
x_bits = [int(b) for b in format(x, '04b')] # [0,1,0,0]
y_bits = [int(b) for b in format(y, '04b')] # [1,0,0,0]
z_bits = [int(b) for b in format(z, '04b')] # [0,1,0,1]
# Combine all bits
all_bits = x_bits + y_bits + z_bits # [0,1,0,0,1,0,0,0,0,1,0,1]
# Initialize a 12-qubit quantum circuit
qc = QuantumCircuit(12)
# Apply x-gates where the bit is 1
for idx, bit in enumerate(all_bits):
if bit == 1:
qc.x(idx)
qc.draw('mpl')
Amplitude encoding
Ang amplitude encoding ay nagko-encode ng data sa mga amplitude ng isang quantum state. Kinakatawan nito ang isang normalized na klasikal na -dimensional na data vector, , bilang mga amplitude ng isang -qubit na quantum state, :
kung saan ang ay ang parehong dimensyon ng mga data vector tulad ng dati, ang ay ang na elemento ng at ang ay ang na computational basis state. Dito, ang ay isang normalization constant na matutukoy mula sa data na ine-encode. Ito ang normalization condition na ipinapataw ng quantum mechanics:
Sa pangkalahatan, ito ay ibang kondisyon kaysa sa min/max normalization na ginagamit para sa bawat feature sa lahat ng data vector. Kung paano ito haharapin ay depende sa iyong problema. Ngunit walang paraan para maiwasan ang quantum mechanical normalization condition sa itaas.
Sa amplitude encoding, bawat feature sa isang data vector ay naka-imbak bilang amplitude ng ibang quantum state. Dahil ang isang sistema ng na qubit ay nagbibigay ng na amplitude, ang amplitude encoding ng na feature ay nangangailangan ng na qubit.
Bilang halimbawa, i-encode natin ang unang vector sa ating halimbawang dataset , ang gamit ang amplitude encoding. Sa pag-normalize ng resultang vector, nakukuha natin:
at ang resultang 2-qubit na quantum state ay magiging:
Sa halimbawa sa itaas, ang bilang ng mga feature sa vector ay hindi isang kapangyarihan ng 2. Kapag ang ay hindi isang kapangyarihan ng 2, pumipili lang tayo ng halaga para sa bilang ng mga qubit na may at dino-dagdagan ang amplitude vector ng mga walang-impormasyon na konstante (dito, isang zero).
Tulad ng sa basis encoding, kapag nakalkulan na natin kung anong estado ang mag-eencode ng ating dataset, sa Qiskit ay maaari nating gamitin ang function na initialize para ihanda ito:
import math
desired_state = [
1 / math.sqrt(105) * 4,
1 / math.sqrt(105) * 8,
1 / math.sqrt(105) * 5,
1 / math.sqrt(105) * 0,
]
qc = QuantumCircuit(2)
qc.initialize(desired_state, [0, 1])
qc.decompose(reps=5).draw(output="mpl")

Isang kalamangan ng amplitude encoding ay ang nabanggit na pangangailangan ng na qubit lamang para mag-encode. Gayunpaman, ang mga kasunod na algorithm ay kailangang gumana sa mga amplitude ng isang quantum state, at ang mga pamamaraan para ihanda at sukatin ang mga quantum state ay karaniwang hindi mahusay.
Suriin ang iyong pag-unawa
Basahin ang mga tanong sa ibaba, isipin ang iyong mga sagot, pagkatapos ay i-click ang mga tatsulok para makita ang mga solusyon.
Isulat ang normalized na estado para sa pag-encode ng sumusunod na vector (na binubuo ng dalawang vector mula sa ating halimbawang dataset):
gamit ang amplitude encoding.
Sagot:
Para mag-encode ng 6 na numero, kailangan nating magkaroon ng hindi bababa sa 6 na available na estado na sa mga amplitude nito ay maaari tayong mag-encode. Mangangailangan ito ng 3 qubit. Gamit ang hindi kilalang normalization factor na , maaari nating isulat ito bilang:
Tandaan na
Kaya sa wakas,
Para sa parehong data vector sumulat ng code para gumawa ng circuit na naglo-load ng mga feature ng data na ito gamit ang amplitude encoding.
Sagot:
desired_state = [
9 / math.sqrt(270),
8 / math.sqrt(270),
6 / math.sqrt(270),
2 / math.sqrt(270),
9 / math.sqrt(270),
2 / math.sqrt(270),
0,
0,
]
print(desired_state)
qc = QuantumCircuit(3)
qc.initialize(desired_state, [0, 1, 2])
qc.decompose(reps=8).draw(output="mpl")
[0.5477225575051662, 0.48686449556014766, 0.36514837167011077, 0.12171612389003691, 0.5477225575051662, 0.12171612389003691, 0, 0]

Maaaring kailangan mong harapin ang napakalalaking mga data vector. Isaalang-alang ang vector
Sumulat ng code para i-automate ang normalization, at gumawa ng quantum circuit para sa amplitude encoding.
Sagot:
Maraming posibleng sagot. Narito ang code na nagpi-print ng ilang hakbang sa daan:
import numpy as np
from math import sqrt
init_list = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0, 3, 7, 5]
qubits = round(np.log(len(init_list)) / np.log(2) + 0.4999999999)
need_length = 2**qubits
pad = need_length - len(init_list)
for i in range(0, pad):
init_list.append(0)
init_array = np.array(init_list) # Unnormalized data vector
length = sqrt(
sum(init_array[i] ** 2 for i in range(0, len(init_array)))
) # Vector length
norm_array = init_array / length # Normalized array
print("Normalized array:")
print(norm_array)
print()
qubit_numbers = []
for i in range(0, qubits):
qubit_numbers.append(i)
print(qubit_numbers)
qc = QuantumCircuit(qubits)
qc.initialize(norm_array, qubit_numbers)
qc.decompose(reps=7).draw(output="mpl")
Normalized array: [0.17342199 0.34684399 0.21677749 0.39019949 0.34684399 0.26013299 0.086711 0.39019949 0.086711 0.21677749 0.30348849 0. 0.1300665 0.30348849 0.21677749 0. ]
[0, 1, 2, 3]
Nakikita ba ang mga kalamangan ng amplitude encoding kumpara sa basis encoding? Kung ganoon, ipaliwanag.
Sagot:
Maaaring may ilang sagot. Isang sagot ay ang, dahil sa nakaayos na pagkakasunud-sunod ng mga basis state, pinapanatili ng amplitude encoding na ito ang pagkakasunud-sunod ng mga numero na ine-encode. Kadalasan ay mas siksik din ang encoding nito.
Isang kalamangan ng amplitude encoding ay ang na qubit lamang ang kailangan para sa isang -dimensional (-feature) na data vector . Gayunpaman, ang amplitude encoding ay karaniwang isang hindi mahusay na proseso na nangangailangan ng arbitrary state preparation, na exponential sa bilang ng CNOT gate. Sa madaling salita, ang state preparation ay may polynomial runtime complexity na sa bilang ng mga dimensyon, kung saan ang , at ang ay ang bilang ng mga qubit. Ang amplitude encoding ay "nagbibigay ng exponential na pagtitipid sa espasyo sa halaga ng exponential na pagtaas sa oras"[3]; gayunpaman, ang mga pagtaas ng runtime patungo sa ay makakamit sa ilang partikular na kaso[4]. Para sa end-to-end quantum speedup, kailangang isaalang-alang ang runtime complexity ng pag-load ng data.
Angle encoding
Ang angle encoding ay may interes sa maraming QML model na gumagamit ng Pauli feature map tulad ng quantum support vector machine (QSVM) at variational quantum circuit (VQC), bukod sa iba pa. Ang angle encoding ay malapit na nauugnay sa phase encoding at dense angle encoding na ipinepresenta sa ibaba. Dito ay gagamitin natin ang "angle encoding" para tumukoy sa isang rotasyon sa , iyon ay, isang rotasyon palayo sa axis na nagagawa halimbawa ng isang gate o isang gate[1,3]. Sa katunayan, maaaring mag-encode ng data sa anumang rotasyon o kombinasyon ng mga rotasyon. Ngunit ang ay karaniwan sa literatura, kaya binibigyang-diin natin ito dito.
Kapag inilapat sa isang qubit, ang angle encoding ay nagdadala ng Y-axis rotation na proporsyonal sa halaga ng data. Isaalang-alang ang encoding ng isang () na feature mula sa na data vector sa isang dataset, :
Bilang alternatibo, maaaring gamitin ang mga gate para sa angle encoding, kahit na ang naka-encode na estado ay magkakaroon ng kumplikadong relative phase kumpara sa .
Ang angle encoding ay naiiba sa dalawang nakaraang pamamaraan na tinalakay sa ilang paraan. Sa angle encoding:
- Ang bawat halaga ng feature ay naimimapa sa isang katumbas na qubit, , na nag-iiwan sa mga qubit sa isang product state.
- Isang numerical na halaga ang ine-encode sa isang pagkakataon, sa halip na isang buong set ng mga feature mula sa isang data point.
- Kailangan ng qubit para sa na data feature, kung saan ang . Madalas na pantay ang dalawa dito. Makikita natin kung paano posible ang sa mga susunod na seksyon.
- Ang resultang circuit ay may constant depth (karaniwang 1 ang depth bago ang transpilation).
Ang constant depth quantum circuit ay partikular na angkop para sa kasalukuyang quantum hardware. Isang karagdagang katangian ng pag-encode ng aming data gamit ang (at lalo na, ang aming pagpili na gumamit ng Y-axis angle encoding) ay gumagawa ito ng mga real-valued quantum state na maaaring maging kapaki-pakinabang para sa ilang partikular na aplikasyon. Para sa Y-axis rotation, ang data ay naimimapa gamit ang isang Y-axis rotation gate na sa pamamagitan ng isang real-valued angle (Qiskit RYGate). Tulad ng sa phase encoding (tingnan sa ibaba), inirerekomenda na i-rescale ang data para ang , na pumipigil sa pagkawala ng impormasyon at iba pang hindi gustong mga epekto.
Ang sumusunod na Qiskit code ay nag-rorate ng isang qubit mula sa paunang estado para mag-encode ng halaga ng data na .
from qiskit.quantum_info import Statevector
from math import pi
qc = QuantumCircuit(1)
state1 = Statevector.from_instruction(qc)
qc.ry(pi / 2, 0) # Phase gate rotates by an angle pi/2
state2 = Statevector.from_instruction(qc)
states = state1, state2
Magtutukoy tayo ng function para ma-visualize ang aksyon sa state vector. Hindi mahalaga ang mga detalye ng kahulugan ng function, ngunit mahalaga ang kakayahang ma-visualize ang mga state vector at ang kanilang mga pagbabago.
import numpy as np
from qiskit.visualization.bloch import Bloch
from qiskit.visualization.state_visualization import _bloch_multivector_data
def plot_Nstates(states, axis, plot_trace_points=True):
"""This function plots N states to 1 Bloch sphere"""
bloch_vecs = [_bloch_multivector_data(s)[0] for s in states]
if axis is None:
bloch_plot = Bloch()
else:
bloch_plot = Bloch(axes=axis)
bloch_plot.add_vectors(bloch_vecs)
if len(states) > 1:
def rgba_map(x, num):
g = (0.95 - 0.05) / (num - 1)
i = 0.95 - g * num
y = g * x + i
return (0.0, y, 0.0, 0.7)
num = len(states)
bloch_plot.vector_color = [rgba_map(x, num) for x in range(1, num + 1)]
bloch_plot.vector_width = 3
bloch_plot.vector_style = "simple"
if plot_trace_points:
def trace_points(bloch_vec1, bloch_vec2):
# bloch_vec = (x,y,z)
n_points = 15
thetas = np.arccos([bloch_vec1[2], bloch_vec2[2]])
phis = np.arctan2(
[bloch_vec1[1], bloch_vec2[1]], [bloch_vec1[0], bloch_vec2[0]]
)
if phis[1] < 0:
phis[1] = phis[1] + 2 * pi
angles0 = np.linspace(phis[0], phis[1], n_points)
angles1 = np.linspace(thetas[0], thetas[1], n_points)
xp = np.cos(angles0) * np.sin(angles1)
yp = np.sin(angles0) * np.sin(angles1)
zp = np.cos(angles1)
pnts = [xp, yp, zp]
bloch_plot.add_points(pnts)
bloch_plot.point_color = "k"
bloch_plot.point_size = [4] * len(bloch_plot.points)
bloch_plot.point_marker = ["o"]
for i in range(len(bloch_vecs) - 1):
trace_points(bloch_vecs[i], bloch_vecs[i + 1])
bloch_plot.sphere_alpha = 0.05
bloch_plot.frame_alpha = 0.15
bloch_plot.figsize = [4, 4]
bloch_plot.render()
plot_Nstates(states, axis=None, plot_trace_points=True)

Isang feature lamang ng isang data vector iyon. Kapag nagko-encode ng na feature sa mga rotation angle ng na qubit, sabihin para sa na data vector ang naka-encode na product state ay magmumukhang ganito:
Tandaan na katumbas ito ng
Suriin ang iyong pag-unawa
Basahin ang mga tanong sa ibaba, isipin ang iyong mga sagot, pagkatapos ay i-click ang mga tatsulok para makita ang mga solusyon.
I-encode ang data vector gamit ang angle encoding, gaya ng inilarawan sa itaas.
Sagot:
qc = QuantumCircuit(3)
qc.ry(0, 0)
qc.ry(2 * math.pi / 4, 1)
qc.ry(2 * math.pi / 2, 2)
qc.draw(output="mpl")

Gamit ang angle encoding gaya ng inilarawan sa itaas, ilang qubit ang kailangan para mag-encode ng 5 feature?
Sagot: 5
Phase encoding
Ang phase encoding ay napaka-katulad ng angle encoding na inilarawan sa itaas. Ang phase angle ng isang qubit ay isang real-valued na anggulo tungkol sa -axis mula sa +-axis. Ang data ay naimimapa gamit ang isang phase rotation, , kung saan ang (tingnan ang Qiskit PhaseGate para sa karagdagang impormasyon). Inirerekomenda na i-rescale ang data para ang . Pinipigilan nito ang pagkawala ng impormasyon at iba pang potensyal na hindi gustong mga epekto[1,2].
Ang isang qubit ay kadalasang ini-initialize sa estado , na isang eigenstate ng phase rotation operator, ibig sabihin ang estado ng qubit ay kailangang i-rotate muna bago maipatupad ang phase encoding. Kaya makatutuwirang i-initialize ang estado gamit ang isang Hadamard gate: . Ang phase encoding sa isang qubit ay nangangahulugang magbigay ng relative phase na proporsyonal sa halaga ng data:
Ang proseso ng phase encoding ay naimimapa ang bawat halaga ng feature sa phase ng isang katumbas na qubit, . Sa kabuuan, ang phase encoding ay may circuit depth na 2, kasama ang Hadamard layer, na ginagawa itong isang mahusay na encoding scheme. Ang phase-encoded multi-qubit state ( qubit para sa na feature) ay isang product state:
Ang sumusunod na Qiskit code ay unang inihahanda ang paunang estado ng isang qubit sa pamamagitan ng pag-rotate nito gamit ang isang Hadamard gate, pagkatapos ay ino-rotate ito muli gamit ang isang phase gate para mag-encode ng feature ng data na .
qc = QuantumCircuit(1)
qc.h(0) # Hadamard gate rotates state down to Bloch equator
state1 = Statevector.from_instruction(qc)
qc.p(pi / 2, 0) # Phase gate rotates by an angle pi/2
state2 = Statevector.from_instruction(qc)
states = state1, state2
qc.draw("mpl", scale=1)

Maaari nating ma-visualize ang rotasyon sa gamit ang function na plot_Nstates na ating tinukoy.
plot_Nstates(states, axis=None, plot_trace_points=True)

Ang Bloch sphere plot ay nagpapakita ng Z-axis rotation kung saan ang . Ang light green na arrow ay nagpapakita ng huling estado.
Ang phase encoding ay ginagamit sa maraming quantum feature map, partikular na ang at feature map, at pangkalahatang Pauli feature map, bukod sa iba pa.
Suriin ang iyong pag-unawa
Basahin ang mga tanong sa ibaba, isipin ang iyong mga sagot, pagkatapos ay i-click ang mga tatsulok para makita ang mga solusyon.
Ilang qubit ang kailangan para gumamit ng phase encoding gaya ng inilarawan sa itaas para mag-imbak ng 8 feature?
Sagot: 8
Sumulat ng code para sa vector gamit ang phase encoding.
Sagot:
Maaaring may maraming sagot. Narito ang isang halimbawa:
phase_data = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0]
qc = QuantumCircuit(len(phase_data))
for i in range(0, len(phase_data)):
qc.h(i)
qc.rz(phase_data[i] * 2 * math.pi / float(max(phase_data)), i)
qc.draw(output="mpl")

Dense angle encoding
Ang dense angle encoding (DAE) ay isang kombinasyon ng angle encoding at phase encoding. Pinapayagan ng DAE ang dalawang halaga ng feature na ma-encode sa isang qubit: isa ay may Y-axis rotation angle, at ang isa pa ay may -axis rotation angle: . Ini-encode nito ang dalawang feature tulad ng sumusunod:
Ang pag-encode ng dalawang feature ng data sa isang qubit ay nagresulta sa na pagbabawas sa bilang ng mga qubit na kailangan para sa encoding. Sa pagpapalawak nito sa mas maraming feature, ang data vector na ay maaaring ma-encode bilang:
Ang DAE ay maaaring palawigin para sa arbitrary na mga function ng dalawang feature sa halip na ang mga sinusoidal na function na ginagamit dito. Ito ay tinatawag na pangkalahatang qubit encoding[7].
Bilang halimbawa ng DAE, ang code sa ibaba ay nagko-code at nagvi-visualize ng encoding ng mga feature at .
qc = QuantumCircuit(1)
state1 = Statevector.from_instruction(qc)
qc.ry(3 * pi / 8, 0)
state2 = Statevector.from_instruction(qc)
qc.rz(7 * pi / 4, 0)
state3 = Statevector.from_instruction(qc)
states = state1, state2, state3
plot_Nstates(states, axis=None, plot_trace_points=True)

Suriin ang iyong pag-unawa
Basahin ang mga tanong sa ibaba, isipin ang iyong mga sagot, pagkatapos ay i-click ang mga tatsulok para makita ang mga solusyon.
Batay sa pagtrato sa itaas, ilang qubit ang kailangan para mag-encode ng 6 na feature gamit ang dense encoding?
Sagot: 3
Sumulat ng code para i-load ang vector gamit ang dense angle encoding.
Sagot:
Tandaan na dino-dagdagan natin ang listahan ng isang "0" para maiwasan ang problema ng pagkakaroon ng isang hindi nagamit na parameter sa ating encoding scheme.
dense_data = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0, 3, 7, 5, 0]
qc = QuantumCircuit(int(len(dense_data) / 2))
entry = 0
for i in range(0, int(len(dense_data) / 2)):
qc.ry(dense_data[entry] * 2 * math.pi / float(max(dense_data)), i)
entry = entry + 1
qc.rz(dense_data[entry] * 2 * math.pi / float(max(dense_data)), i)
entry = entry + 1
qc.draw(output="mpl")

Pag-encode gamit ang mga built-in na feature map
Pag-encode sa mga arbitrary na punto
Ang angle encoding, phase encoding, at dense encoding ay naghahanda ng mga product state na may isang feature na naka-encode sa bawat qubit (o dalawang feature bawat qubit). Ito ay naiiba sa basis encoding at amplitude encoding, dahil ang mga pamamaraang iyon ay gumagamit ng mga entangled state. Walang 1:1 na ugnayan sa pagitan ng isang data feature at isang qubit. Sa amplitude encoding, halimbawa, maaaring may isang feature bilang amplitude ng state at isa pang feature bilang amplitude ng . Sa pangkalahatan, ang mga pamamaraang nag-e-encode sa product states ay nagbubunga ng mas mababaw na circuits at kayang mag-imbak ng 1 o 2 na feature sa bawat qubit. Ang mga pamamaraang gumagamit ng entanglement at nag-uugnay ng isang feature sa isang state sa halip na sa isang qubit ay nagbubunga ng mas malalim na circuits, at kayang mag-imbak ng mas maraming feature bawat qubit sa karaniwan.
Ngunit hindi kailangang maging ganap na nasa product states o ganap na nasa entangled states ang encoding tulad ng sa amplitude encoding. Sa katunayan, maraming encoding scheme na built-in sa Qiskit ang nagpapahintulot ng encoding bago at pagkatapos ng isang entanglement layer, kumpara sa pag-encode lamang sa simula. Ito ay tinatawag na "data reuploading". Para sa kaugnay na pananaliksik, tingnan ang mga sanggunian [5] at [6].
Sa seksyong ito, gagamitin at ivi-visualize natin ang ilang built-in na encoding scheme. Lahat ng pamamaraan sa seksyong ito ay nag-e-encode ng na feature bilang mga rotasyon sa na parameterized gate sa qubit, kung saan . Tandaan na ang pag-maximize ng data loading para sa isang tiyak na bilang ng qubit ay hindi lang ang dapat isaalang-alang. Sa maraming kaso, ang lalim ng circuit ay maaaring mas mahalaga pa kaysa sa bilang ng qubit.
Efficient SU2
Isang karaniwang at kapaki-pakinabang na halimbawa ng pag-encode na may entanglement ay ang efficient_su2 circuit ng Qiskit. Kahanga-hanga, ang circuit na ito ay kayang, halimbawa, mag-encode ng 8 na feature sa 2 qubit lamang. Tignan natin ito, at pagkatapos ay subukang unawain kung paano ito posible.
from qiskit.circuit.library import efficient_su2
circuit = efficient_su2(num_qubits=2, reps=1, insert_barriers=True)
circuit.decompose().draw(output="mpl")

Habang isinusulat natin ang ating state, gagamitin natin ang Qiskit convention na ang mga least-significant qubit ay nakaayos sa pinakakanang bahagi, tulad ng sa o Ang mga state na ito ay maaaring maging napakakumplikado agad, at ang bihirang halimbawang ito ay makakatulong na ipaliwanag kung bakit bihira nang isinusulat ang mga ganitong state nang tahasan.
Nagsisimula ang ating sistema sa state Hanggang sa unang barrier (isang puntong tinutukoy natin bilang ), ang ating mga state ay:
Ito ay dense encoding lamang, na nakita na natin noon. Ngayon pagkatapos ng CNOT gate, sa ikalawang barrier (), ang ating state ay
Ngayon ay ilalagay natin ang huling set ng mga single-qubit rotation at pagsamahin ang mga magkaparehong state upang makuha:
Malamang na masyadong kumplikado itong suriin. Sa halip, huminto muna at isipin kung ilang parameter ang na-load natin sa state: walo. Ngunit mayroon lamang tayong apat na computational basis state. Sa unang tingin, maaaring mukhang nag-load tayo ng mas maraming parameter kaysa sa makatuwiran, dahil ang final state ay maaaring isulat bilang . Tandaan, gayunpaman, na ang bawat prefactor ay complex! Isinulat tulad nito:
Makikita ng isa na mayroon nga tayong walong parameter sa state kung saan maaari nating i-encode ang ating walong feature.
Sa pamamagitan ng pagdaragdag ng bilang ng qubit at pagdaragdag ng bilang ng pag-uulit ng mga entangling at rotation layer, maaaring mag-encode ng mas maraming data. Ang pagsulat ng mga wave function ay mabilis na magiging hindi maisakatuparan. Ngunit makikita pa rin natin ang encoding sa aksyon.
Dito ay ine-encode natin ang data vector na may 12 feature, sa isang 3-qubit na efficient_su2 circuit, gamit ang bawat isa sa mga parameterized gate upang i-encode ang ibang feature.
Sa data vector na ito, ang mga feature ay ipinapakita sa isang partikular na pagkakasunod-sunod. Sa pangkalahatan, hindi mahalaga kung ine-encode ang mga ito sa pagkakasunod-sunod na ito o sa kabaligtaran. Ang mahalaga ay ang pagsubaybay nito at pagiging konsistente. Tandaan sa circuit diagram na ang efficient_su2 ay nagtatanggap ng isang tiyak na pagkakasunod-sunod ng encoding, partikular na pinupuno ang unang layer ng mga parameterized gate mula sa qubit 0 hanggang qubit 2, at pagkatapos ay pumunta sa susunod na layer. Ito ay hindi konsistente ni hindi rin hindi-konsistente sa little-endian notation, dahil dito ang mga data feature ay hindi maaaring maayos ayon sa qubit a priori, bago pa tukuyin ang isang encoding circuit.
x = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0, 1.1, 1.2]
circuit = efficient_su2(num_qubits=3, reps=1, insert_barriers=True)
encode = circuit.assign_parameters(x)
encode.decompose().draw(output="mpl")

Sa halip na dagdagan ang bilang ng qubit, maaari kang pumili na dagdagan ang bilang ng pag-uulit ng mga entangling at rotation layer. Ngunit may mga limitasyon sa kung gaano karaming pag-uulit ang kapaki-pakinabang. Tulad ng nabanggit kanina, may kapalit: ang mga circuit na may mas maraming qubit o mas maraming pag-uulit ng mga entangling at rotation layer ay maaaring mag-imbak ng mas maraming parameter, ngunit ginagawa ito nang may mas malaking lalim ng circuit. Babalik tayo sa mga lalim ng ilang built-in na feature map, sa ibaba. Ang susunod na ilang encoding method na built-in sa Qiskit ay may "feature map" bilang bahagi ng kanilang mga pangalan. Ulitin natin na ang pag-encode ng data sa isang quantum circuit ay isang feature mapping, sa kahulugang kinukuha nito ang data papunta sa bagong espasyo: ang Hilbert space ng mga qubit na kasangkot. Ang relasyon sa pagitan ng dimensionality ng orihinal na feature space at ng Hilbert space ay depende sa circuit na ginagamit mo para sa encoding.
feature map
Ang feature map (ZFM) ay maaaring bigyang-kahulugan bilang natural na extension ng phase encoding. Ang ZFM ay binubuo ng mga nahaliling layer ng single-qubit gate: mga Hadamard gate layer at mga phase gate layer. Hayaan ang data vector na magkaroon ng na feature. Ang quantum circuit na nagsasagawa ng feature mapping ay kinakatawan ng isang unitary operator na kumikilos sa initial state:
kung saan ang ay ang -qubit ground state. Ginagamit ang notation na ito para sa konsistensya sa sanggunian [4] Havlicek et al. Ang mga data feature na ay naka-map nang isa-isa sa mga katumbas na qubit. Halimbawa, kung mayroon kang 8 na feature sa isang data vector, gagamit ka ng 8 qubit. Ang ZFM circuit ay binubuo ng na pag-uulit ng isang subcircuit na binubuo ng mga Hadamard gate layer at phase gate layer. Ang isang Hadamard layer ay binubuo ng isang Hadamard gate na kumikilos sa bawat qubit sa isang -qubit register, , sa parehong yugto ng algorithm. Naaangkop din ang paglalarawang ito sa isang phase gate layer kung saan ang qubit ay kinikilos ng . Ang bawat gate ay may isang feature bilang argumento, ngunit ang phase gate layer ( ay isang function ng data vector. Ang buong ZFM circuit unitary na may isang pag-uulit ay:
Kung gayon ang na pag-uulit ng unitary na ito ay magiging
Ang mga data feature, , ay naka-map sa mga phase gate sa parehong paraan sa lahat ng na pag-uulit. Ang ZFM feature map state ay isang product state at mahusay para sa classical simulation[4].
Upang magsimula sa isang maliit na halimbawa, isang two-qubit ZFM circuit ang kinocode gamit ang Qiskit at iginuhit upang ipakita ang simpleng circuit structure. Sa halimbawa, isang pag-uulit, , ang isinasagawa kasama ang data vector . Tandaan na ito ay isinulat sa standard na pagkakasunod-sunod ng isang vector sa Python, ibig sabihin ang elemento ay Malaya tayong i-encode ang feature na ito sa ating qubit, o sa ating Muli, hindi palaging maaaring magkaroon ng isang 1:1 na pagmamapa mula sa pagkakasunod-sunod ng feature patungo sa pagkakasunod-sunod ng qubit, dahil ang iba't ibang feature map ay nag-e-encode ng iba't ibang bilang ng feature sa bawat qubit. Muli ang mahalaga ay alam natin kung saan naka-encode ang bawat feature. Kapag nagbibigay ng listahan ng parameter sa feature map, ine-encode nito ang feature 0 mula sa listahan sa least-significant qubit na may parameterized gate, tulad ng qubit 0. Kaya susunod tayo sa convention na iyon kapag ginagawa ito nang manu-mano. Ine-encode natin ang sa qubit, at sa qubit.
Ang ZFM circuit unitary operator ay kumikilos sa initial state sa sumusunod na paraan:
Ang formula ay muling inayos sa paligid ng tensor product upang bigyang-diin ang mga operasyon sa bawat qubit. Ang sumusunod na Qiskit code ay gumagamit ng Hadamard at phase gate nang tahasan upang ipakita ang istraktura ng ZFM:
qc0 = QuantumCircuit(1)
qc1 = QuantumCircuit(1)
qc0.h(0)
qc0.p(pi / 2, 0)
qc1.h(0)
qc1.p(pi / 3, 0)
# Combine circuits qc0 and qc1 into 1 circuit
qc = QuantumCircuit(2)
qc.compose(qc0, [0], inplace=True)
qc.compose(qc1, [1], inplace=True)
qc.draw("mpl", scale=1)

Ngayon ine-encode natin ang parehong data vector sa isang ZFM circuit na may tatlong pag-uulit, , gamit ang Qiskit z_feature_map class, na sa kabuuan ay nagbibigay sa atin ng quantum feature map . Bilang default sa z_feature_map class, ang mga parameter ay pinarami ng 2 bago i-map sa phase gate . Upang makuha ang parehong mga encoding tulad ng nasa itaas, hinahati natin sa 2.
from qiskit.circuit.library import z_feature_map
zfeature_map = z_feature_map(feature_dimension=2, reps=3)
zfeature_map = zfeature_map.assign_parameters([(1 / 2) * pi / 2, (1 / 2) * pi / 3])
zfeature_map.decompose().draw("mpl")

Malinaw na ito ay ibang pagmamapa mula sa ginawa nang manu-mano sa itaas, ngunit tandaan ang konsistensya sa pagkakasunod-sunod ng parameter: ang ay na-encode muli sa qubit.
Maaari kang gumamit ng ZFM sa pamamagitan ng ZFM class ng Qiskit; maaari mo ring gamitin ang istrukturang ito bilang inspirasyon upang bumuo ng sarili mong feature mapping.
feature map
Ang feature map (ZZFM) ay nagpapalawak ng ZFM sa pamamagitan ng pagsasama ng mga two-qubit entangling gate, partikular ang -rotation gate . Ang ZZFM ay pinaghihinalaang karaniwang mahal kalkulahin sa isang classical computer, hindi tulad ng ZFM.
Ipinapatupad ng ang isang -interaction at pinaka-entangling para sa . Ang ay maaaring i-decompose sa isang serye ng mga gate sa dalawang qubit, tulad ng ipinakita sa sumusunod na Qiskit code gamit ang RZZ gate at ang QuantumCircuit class method decompose. Ine-encode natin ang isang feature ng data vector :
qc = QuantumCircuit(2)
qc.rzz(pi, 0, 1)
qc.draw("mpl", scale=1)

Tulad ng madalas na nangyayari, makikita natin itong kinakatawan bilang isang solong gate-like na yunit, hanggang sa gamitin natin ang .decompose() upang makita ang lahat ng constituent gate.
qc.decompose().draw("mpl", scale=1)

Ang data ay naka-map na may phase rotation na sa ikalawang qubit. Ang gate ay nag-e-entangle ng dalawang qubit kung saan ito kumikilos ayon sa antas ng entanglement na tinutukoy ng naka-encode na feature value.
Ang buong ZZFM circuit ay binubuo ng isang Hadamard gate at phase gate, tulad ng sa ZFM, na sinusundan ng entanglement na inilarawan sa itaas. Ang isang pag-uulit ng ZZFM circuit ay:
kung saan ang ay naglalaman ng ZZ-gate layer na nakaayos ng isang entanglement scheme. Maraming entanglement scheme ang ipinapakita sa mga code block sa ibaba. Ang istraktura ng ay nagsasama rin ng isang function na nagpagsasama ng mga data feature mula sa mga qubit na ine-entangle sa sumusunod na paraan. Sabihin nating ang gate ay ilalapat sa mga qubit at . Sa phase layer, ang mga qubit na ito ay may mga phase gate na nag-e-encode ng at sa kanila, ayon sa pagkakasunod-sunod. Ang argumento ng ay hindi lamang isa sa mga feature na ito o ang isa pa, kundi isang function na madalas na tinutukoy ng (huwag itong ipagkamaliang may azimuthal angle):
Makikita natin ito sa ilang halimbawa sa ibaba. Ang extension sa maraming pag-uulit ay kapareho ng sa kaso ng z_feature_map:
Dahil ang mga operator ay naging mas kumplikado, i-encode muna natin ang isang data vector gamit ang isang two-qubit ZZFM na may isang pag-uulit gamit ang sumusunod na code:
from qiskit.circuit.library import zz_feature_map
feature_dim = 2
zzfeature_map = zz_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1
)
zzfeature_map.decompose(reps=1).draw("mpl", scale=1)

Bilang default sa Qiskit, ang mga feature ay pinagsama-samang naka-map sa sa pamamagitan ng mapping function na . Nagbibigay ang Qiskit sa gumagamit ng kakayahang i-customize ang function (o kung saan ang set ng mga qubit pair na nakakonekta sa pamamagitan ng gate) bilang isang preprocessing step.
Lumipat sa isang four-dimensional na data vector at i-map sa isang four-qubit ZZFM na may isang pag-uulit, maaari na tayong magsimulang makita ang pagmamapa para sa iba't ibang qubit pair. Makikita rin natin ang kahulugan ng "linear" entanglement:
feature_dim = 4
zzfeature_map = zz_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1
)
zzfeature_map.decompose().draw("mpl", scale=1)

Sa linear entanglement scheme, ang mga nearest-neighbor (na may numero) na pares ng qubit sa circuit na ito ay ine-entangle. Mayroon pang iba pang built-in na entanglement scheme sa Qiskit, kabilang ang circular at full.
Pauli feature map
Ang Pauli feature map (PFM) ay ang generalization ng ZFM at ZZFM upang gumamit ng mga arbitrary na Pauli gate. Ang Pauli feature map ay may napaka-katulad na anyo sa nakaraang dalawang feature map. Para sa na pag-uulit ng encoding ng na feature ng vector
Para sa PFM, ang ay generalize sa isang Pauli expansion unitary operator. Dito ay nagpapakita tayo ng mas generalized na anyo ng mga feature map na isinaalang-alang nang to ngayon:
kung saan ang ay isang Pauli operator, . Dito ang ay ang set ng lahat ng qubit connectivity na tinutukoy ng feature map, kabilang ang set ng mga qubit na kinikilos ng mga single-qubit gate. Iyon ay, para sa isang feature map kung saan kumikilos ang isang phase gate sa qubit 0, at kumikilos ang isang gate sa mga qubit 2 at 3, ang set ay magsasama ng . Ang ay dumadaan sa lahat ng elemento ng set na iyon. Sa mga naunang feature map, ang function ay may kaugnayan nang eksklusibo sa mga single-qubit gate o eksklusibo sa mga two-qubit gate. Dito, tinutukoy natin ito sa pangkalahatan:
Para sa dokumentasyon, tingnan ang Qiskit Pauli feature map class documentation). Sa ZZFM, ang operator ay limitado sa .
Isang paraan upang maunawaan ang unitary sa itaas ay sa pamamagitan ng pagkakatulad sa propagator sa isang pisikal na sistema. Ang unitary sa itaas ay isang unitary evolution operator, , para sa isang Hamiltonian, , na katulad ng Ising model, kung saan ang time parameter, , ay pinapalitan ng mga data value upang patakbuhin ang evolution. Ang expansion ng unitary operator na ito ay nagbibigay ng PFM circuit. Ang mga entangling connectivity sa ay maaaring bigyang-kahulugan bilang mga Ising coupling sa isang spin lattice.
Isaalang-alang natin ang isang halimbawa ng Pauli at operator na kumakatawan sa mga ganitong Ising-type na interaksyon. Nagbibigay ang Qiskit ng pauli_feature_map class para sa pag-instantiate ng PFM na may pagpipilian ng mga single- at -qubit gate, na sa halimbawang ito ay ipapasa bilang Pauli strings 'Y' at 'XX'. Karaniwan, ang ay 1 o 2 para sa mga single- at two-qubit na interaksyon, ayon sa pagkakasunod-sunod. Ang entanglement scheme ay "linear," ibig sabihin ang mga nearest-neighbor na qubit lamang sa quantum circuit ang nakakonekta. Tandaan na hindi ito katumbas ng mga nearest-neighbor na qubit sa aktwal na quantum computer, dahil ang quantum circuit na ito ay isang abstraction layer.
from qiskit.circuit.library import pauli_feature_map
feature_dim = 3
pfmap = pauli_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1, paulis=["Y", "XX"]
)
pfmap.decompose().draw("mpl", scale=1.5)

Nagbibigay ang Qiskit ng parameter, , sa mga Pauli feature map upang kontrolin ang scaling ng mga Pauli rotation.
Ang default na value ng ay . Sa pamamagitan ng pag-optimize ng halaga nito sa interval, halimbawa, maaaring mas maayos na i-align ang isang quantum kernel sa data.
Gallery ng mga Pauli feature map
Dito ay vivi-visualize natin ang iba't ibang Pauli feature map para sa mga two-qubit circuit upang makakuha ng mas malinaw na larawan ng hanay ng mga posibilidad.
from qiskit.visualization import circuit_drawer
import matplotlib.pyplot as plt
feature_dim = 2
fig, axs = plt.subplots(9, 2)
i_plot = 0
for paulis in [
["I"],
["X"],
["Y"],
["Z"],
["XX"],
["XY"],
["XZ"],
["YY"],
["YZ"],
["ZZ"],
["X", "ZZ"],
["Y", "ZZ"],
["Z", "ZZ"],
["X", "YZ"],
["Y", "YZ"],
["Z", "YZ"],
["YY", "ZZ"],
["XY", "ZZ"],
]:
pfmap = pauli_feature_map(feature_dimension=feature_dim, paulis=paulis, reps=1)
circuit_drawer(
pfmap.decompose(),
output="mpl",
style={"backgroundcolor": "#EEEEEE"},
ax=axs[int((i_plot - i_plot % 2) / 2), i_plot % 2],
)
axs[int((i_plot - i_plot % 2) / 2), i_plot % 2].title.set_text(paulis)
i_plot += 1
fig.set_figheight(16)
fig.set_figwidth(16)
Ang nasa itaas ay maaaring, siyempre, palawigin upang isama ang iba pang permutasyon at pag-uulit ng mga Pauli matrices. Hinihikayat ang mga mag-aaral na mag-eksperimento sa mga opsyong iyon.
Pagsusuri ng mga built-in na feature map
Nakita mo na ang ilang scheme para sa pag-encode ng data sa isang quantum circuit:
- Basis encoding
- Amplitude encoding
- Angle encoding
- Phase encoding
- Dense encoding
Nakita mo kung paano bumuo ng sarili mong mga feature map gamit ang mga encoding scheme na ito, at nakita mo ang apat na built-in na feature map na sinasamantala ang angle at phase encoding:
- Efficient SU2
- Z feature map
- ZZ feature map
- Pauli feature map
Ang mga built-in na feature map na ito ay nagkaiba-iba sa isa't isa sa ilang paraan:
- Ang lalim para sa isang tiyak na bilang ng mga naka-encode na feature
- Ang bilang ng qubit na kinakailangan para sa isang tiyak na bilang ng feature
- Ang antas ng entanglement (malinaw na may kaugnayan sa iba pang pagkakaiba)
Ang code sa ibaba ay inilalapat ang apat na built-in na feature map na ito sa pag-encode ng isang feature set, at nipo-plot ang two-qubit depth ng resultang circuit. Dahil ang mga two-qubit error rate ay mas mataas kaysa sa mga single-qubit gate error rate, maaaring makatuwiran na pinaka-interesado ang isa sa lalim ng mga two-qubit gate. Sa code sa ibaba, nakukuha natin ang mga bilang ng lahat ng gate sa isang circuit sa pamamagitan ng pag-decompose muna ng circuit at pagkatapos ay paggamit ng count_ops(), tulad ng ipinapakita sa ibaba. Dito ang mga two-qubit gate na interesado tayo ay ang mga 'cx' gate:
# Initializing parameters and empty lists for depths
x = [0.1, 0.2]
n_data = []
zz2gates = []
su22gates = []
z2gates = []
p2gates = []
# Generating feature maps
for n in range(3, 10):
x.append(n / 10)
zzcircuit = zz_feature_map(n, reps=1, insert_barriers=True)
zcircuit = z_feature_map(n, reps=1, insert_barriers=True)
su2circuit = efficient_su2(n, reps=1, insert_barriers=True)
pcircuit = pauli_feature_map(n, reps=1, paulis=["XX"], insert_barriers=True)
# Getting the cx depths
zzcx = zzcircuit.decompose().count_ops().get("cx")
zcx = zcircuit.decompose().count_ops().get("cx")
su2cx = su2circuit.decompose().count_ops().get("cx")
pcx = pcircuit.decompose().count_ops().get("cx")
# Appending the cx gate counts to the lists. We shift the zz and Pauli data points,
# because they overlap.
n_data.append(n)
zz2gates.append(zzcx - 0.5)
z2gates.append(0)
su22gates.append(su2cx)
p2gates.append(pcx + 0.5)
# Plot the output
plt.plot(n_data, p2gates, "bo")
plt.plot(n_data, zz2gates, "ro")
plt.plot(n_data, su22gates, "yo")
plt.plot(n_data, z2gates, "go")
plt.ylabel("CX Gates")
plt.xlabel("Data elements")
plt.legend(["Pauli", "ZZ", "SU2", "Z"])
# plt.suptitle('zz_feature_map(n)')
plt.show()
Sa pangkalahatan, ang mga Pauli at ZZ feature map ay magbubunga ng mas malaking lalim ng circuit at mas mataas na bilang ng 2-qubit gate kaysa sa efficient_su2 at Z feature map.
Dahil ang mga feature map na built-in sa Qiskit ay malawak na naaangkop, madalas na hindi na tayo kailangang mag-disenyo ng sarili nating feature map, lalo na sa yugto ng pag-aaral. Gayunpaman, ang mga eksperto sa quantum machine learning ay malamang na babalik sa paksa ng pagdidisenyo ng sarili nilang feature mapping, habang tinutugunan nila ang dalawang kumplikadong hamon:
-
Modernong hardware: ang presensya ng ingay at ang malaking overhead ng error-correcting code ay nangangahulugang ang mga kasalukuyang aplikasyon ay kailangang isaalang-alang ang mga bagay tulad ng hardware efficiency at pag-minimize ng two-qubit gate depth.
-
Mga pagmamapa na angkop sa problema: Isa itong bagay na sabihin na ang
zz_feature_map, halimbawa, ay mahirap i-simulate nang klasikal, at samakatuwid ay kawili-wili. Ibang usapan na angzz_feature_mapay perpektong angkop sa iyong machine learning task o dataset. Ang pagganap ng iba't ibang parameterized quantum circuit sa iba't ibang uri ng data ay isang aktibong larangan ng pananaliksik.
Magtatapos tayo sa isang tala tungkol sa hardware efficiency.
Hardware-efficient na feature mapping
Ang isang hardware-efficient na feature mapping ay isa na isinasaalang-alang ang mga hadlang ng totoong quantum computer, sa layuning mabawasan ang ingay at mga error sa computation. Kapag nagpapatakbo ng mga quantum circuit sa mga near-term quantum computer, maraming estratehiya upang mabawasan ang ingay na likas sa hardware. Ang isang pangunahing estratehiya para sa hardware efficiency ay ang pag-minimize ng lalim ng quantum circuit upang ang ingay at decoherence ay may mas kaunting oras upang masira ang computation. Ang lalim ng isang quantum circuit ay ang bilang ng mga time-aligned na gate step na kinakailangan upang makumpleto ang buong computation (pagkatapos ng circuit optimization)[5]. Tandaan na ang lalim ng abstract, logical circuit ay maaaring mas mababa kaysa sa lalim kapag na-transpile na ang circuit para sa isang totoong quantum computer.
Ang transpilation ay ang proseso ng pag-convert ng quantum circuit mula sa isang mataas na antas ng abstraction patungo sa isa na handa nang patakbuhin sa isang totoong quantum computer, isinasaalang-alang ang mga hadlang ng hardware. Ang isang quantum computer ay may native na set ng mga single- at two-qubit gate. Ibig sabihin, lahat ng gate sa Qiskit code ay kailangang i-transpile sa set ng mga native hardware gate. Halimbawa, sa ibm_torino, isang QPU na gumagamit ng Heron r1 processor at natapos noong 2023, ang mga native o basis gate ay {CZ, ID, RZ, SX, X}. Ito ang two-qubit controlled-Z gate, at mga single-qubit gate na tinatawag na identity, -rotation, square root of NOT, at NOT, ayon sa pagkakasunod-sunod, na nagbibigay ng universal set. Kapag isinasagawa ang mga multi-qubit gate bilang isang katumbas na subcircuit, kinakailangan ang mga pisikal na two-qubit gate, kasama ng iba pang single-qubit gate na available sa hardware. Bukod pa rito, upang magsagawa ng two-qubit gate sa isang pares ng qubit na hindi pisikal na nakakonekta, ang mga SWAP gate ay idinaragdag upang ilipat ang mga qubit state sa pagitan ng mga qubit upang paganahin ang coupling, na humahantong sa hindi maiiwasang pagpapahaba ng circuit. Gamit ang optimization na argumento na maaaring itakda mula 0 hanggang sa pinakamataas na antas na 3. Para sa mas malaking kontrol at customizability, ang transpiler pipeline ay maaaring pamahalaan gamit ang Qiskit Pass Manager. Tingnan ang Qiskit Transpiler documentation para sa karagdagang impormasyon sa transpilation.
Sa Havlicek et al. 2019 [2], isang paraan na nakamit ng mga may-akda ang hardware efficiency ay sa pamamagitan ng paggamit ng feature map dahil ito ay isang second-order expansion (tingnan ang seksyon ng " feature map" sa itaas). Ang isang -order expansion ay may mga -qubit gate. Ang IBM® quantum computer ay walang native na -qubit gate, kung saan , kaya ang pagpapatupad ng mga ito ay mangangailangan ng decomposition sa mga two-qubit CNOT gate na available sa hardware. Ang ikalawang paraan na mino-minimize ng mga may-akda ang lalim ay sa pamamagitan ng pagpili ng coupling topology na direktang naka-map sa mga architecture coupling. Ang karagdagang optimisasyon na isinasagawa nila ay ang pag-target ng isang mas mataas na pagganap, sapat na nakakonektang hardware subcircuit. Karagdagang mga bagay na dapat isaalang-alang ay ang pag-minimize ng bilang ng mga pag-uulit ng feature map at pagpili ng customized na mababang lalim o "linear" na entangling scheme sa halip ng "full" scheme na nag-e-entangle ng lahat ng qubit.

Ang graphic sa itaas ay nagpapakita ng network ng mga node at edge na kumakatawan sa mga pisikal na qubit at hardware coupling, ayon sa pagkakasunod-sunod. Ang coupling map at pagganap ng ibm_torino ay ipinapakita kasama ang lahat ng posibleng two-qubit CZ coupling gate. Ang mga qubit ay naka-color-code sa isang scale batay sa T1 relaxation time sa microsecond (μs), kung saan ang mas mahabang T1 time ay mas mabuti at nasa mas maliwanag na kulay. Ang mga coupling edge ay naka-color-code sa pamamagitan ng CZ error, kung saan ang mas madilim na kulay ay mas mabuti. Ang impormasyon sa hardware specification ay maaaring ma-access sa hardware backend configuration schema IBMQBackend.configuration().
Mga Sanggunian
- Maria Schuld and Francesco Petruccione, Supervised Learning with Quantum Computers, Springer 2018, doi:10.1007/978-3-319-96424-9.
- Vojtech Havlicek et al., "Supervised Learning with Quantum Enhanced Feature Spaces." Nature, vol. 567 (2019): 209–212. https://arxiv.org/abs/1804.11326.
- Ryan LaRose and Brian Coyle, "Robust data encodings for quantum classifiers", Physical Review A 102, 032420 (2020), doi:10.1103/PhysRevA.102.032420, arXiv:2003.01695.
- Lou Grover and Terry Rudolph. "Creating Superpositions That Correspond to Efficiently Integrable Probability Distributions." arXiv:quant-ph/0208112, August 15, 2002, https://arxiv.org/abs/quant-ph/0208112.
- Adrián Pérez-Salinas, Alba Cervera-Lierta, Elies Gil-Fuster, José I. Latorre, "Data re-uploading for a universal quantum classifier", Quantum 4, 226 (2020), ArXiv.org/abs/1907.02085.
- Maria Schuld, Ryan Sweke, Johannes Jakob Meyer, "The effect of data encoding on the expressive power of variational quantum machine learning models", Phys. Rev. A 103, 032430 (2021), arxiv.org/abs/2008.08605
import qiskit
qiskit.version.get_version_info()